Microserviços e o problema do Dual Write

Hoje vamos falar de um problema quase sempre negligenciado pelos desenvolvedores em seus microsserviços (pelo menos até que aconteça e estrague sua sexta-feira), conheça um pouco mais sobre o dual write.
Contexto
Dado o seguinte cenário:

Veja que:
- Serviço #1 executa duas operações de escrita, uma em uma fila do Kafka e outra em um banco de dados
- Ambas operações ocorrem no mesmo “método”, em uma mesma transação
- Podemos assumir não haver garantia de que o Kafka ou banco de dados vão estar disponíveis
O método que faria esta operação poderia ser escrito como:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public class PedidoService {
private final PedidoRespository pedidoRespository;
private final StatusDoPedidoPublisher statusDoPedidoPublisher;
// construtor e lombok omitidos
public void despacharPedido(Pedido pedido) {
pedido.setParaDespachado();
pedidoRespository.atualizarStatus(pedido);
statusDoPedidoPublisher.publicarPedidoDespachado(pedido);
}
}
Observe que se houver um problema no processo de gravação no banco de dados nada de ruim irá acontecer, porém, caso uma falha na publicação para o Kafka ocorra, estaremos com nosso estado no banco de dados inconsistente visto que o pedido foi atualizado, mas não foi efetivamente despachado.
Este é o dual write em sua forma mais comum, quando temos duas operações de escrita, na mesma transação e em caso de falha de uma das operações (no caso a última, linha 13) nosso sistema estará em um estado inconsistente onde talvez um replay da operação possa gerar efeitos colaterais indesejados.
Possíveis soluções
Eu vejo com certa frequência alguns desenvolvedores simplesmente ignorarem este problema, eu mesmo já estive nessa posição de dizer “não temos isso acontecendo ainda, vamos deixar assim”.
O fato é que em aplicações com alto volume de dados não há como ignorar algo assim, mas em sistema ainda em etapas iniciais e com um volume de dados controlado podemos nos dar a esse “luxo” visto que o dual write foi “criado” ali devido à solução ainda estar em evolução e aquele código pode potencialmente ser refatorado depois em um dos ciclos de melhoria.
Considerando o cenário onde não temos esse “luxo”, algumas possibilidades podem ser levantadas:
- Publicar o evento primeiro e gravar no banco depois
- Publicar o evento depois do commit no banco através de uma listener
Sobre o item 1, não há muito o que falar, basicamente estamos complicando mais contexto! Imagine que uma das listeners do evento seja um serviço de envio de e-mail e uma falha no processo de gravar no banco acontece? O cliente foi notificado que o pedido foi despachado, mas, na verdade, ele ainda não foi.
Sobre o item 2, em um primeiro momento parece viável, mas, haveria uma complicação imensa para realizar o controle da excessão e sair dando desfazendo as alterações.
Outbox patter to the rescue
Em resumo, o outbox pattern consiste em gravar os dados pertinentes ao evento que precisamos enviar em uma nova tabela, ou seja, estaríamos lidando com apenas um tipo de data store (no caso, o banco de dados) e isso vai nos facilitar manter a consistência visto que podemos usar o mecanismo próprio do banco para garantir que, caso haja algum problema, tudo que foi feito naquela transação seja desfeito.
Atualizando nosso desenho, seria algo assim:
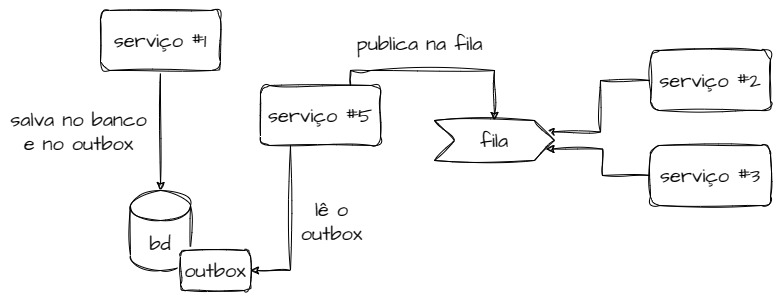
Repare que agora nosso serviço lida apenas com o banco de dados, fazendo a atualização do pedido e em seguida salvando o outbox para o evento do Kafka ser publicado.
O outbox consiste em nada mais que uma tabela no banco de dados com apenas as informações necessárias para que o nosso evento seja enviado, um novo serviço seria criado com apenas um único propósito: enviar os eventos quando um novo outbox for gerado.
Simples né? Nem tanto! Esse é basicamente o conceito de como usar o outbox para definitivamente resolver o problema do dual write. Entenderam agora porque eu disse que talvez, para sistema ainda em evolução ou que não estão em sua forma “final” usar solucionar o dual write talvez seja muito complicado?
Algumas pessoas (mais das antigas talvez hahaha) podem até pensar que utilizar um outbox é basicamente uma maneira mais “fashion” de se fazer integrações usando o banco de dados, e realmente, é!
Outras soluções
Felizmente o mundo da programação é muito rico em soluções mapeadas para problemas já conhecidos, os famosos patterns e nesse contexto não, seria diferente.
Existem outros meios de se resolver um dual write e vou deixar aqui em baixo um link para uma dessas outras maneiras, utilizando o SAGA pattern:
Este post tem uma continuação, você pode acessá-la aqui
Referências
- https://thorben-janssen.com/dual-writes/
- https://www.johnnyhashoul.com/post/dual-write-and-data-inconsistency
- https://learn.microsoft.com/en-us/dynamics365/fin-ops-core/dev-itpro/data-entities/dual-write/dual-write-overview
- https://www.confluent.io/blog/using-logs-to-build-a-solid-data-infrastructure-or-why-dual-writes-are-a-bad-idea/